
In the context of GenAI applications, a vector embedding (or simply a vector) is a sequence of numbers associated with some data. This sequence of numbers captures the semantic meaning of the associated data, and each number represents a feature. For example, the following is a vector embedding that represents an image of a dog:
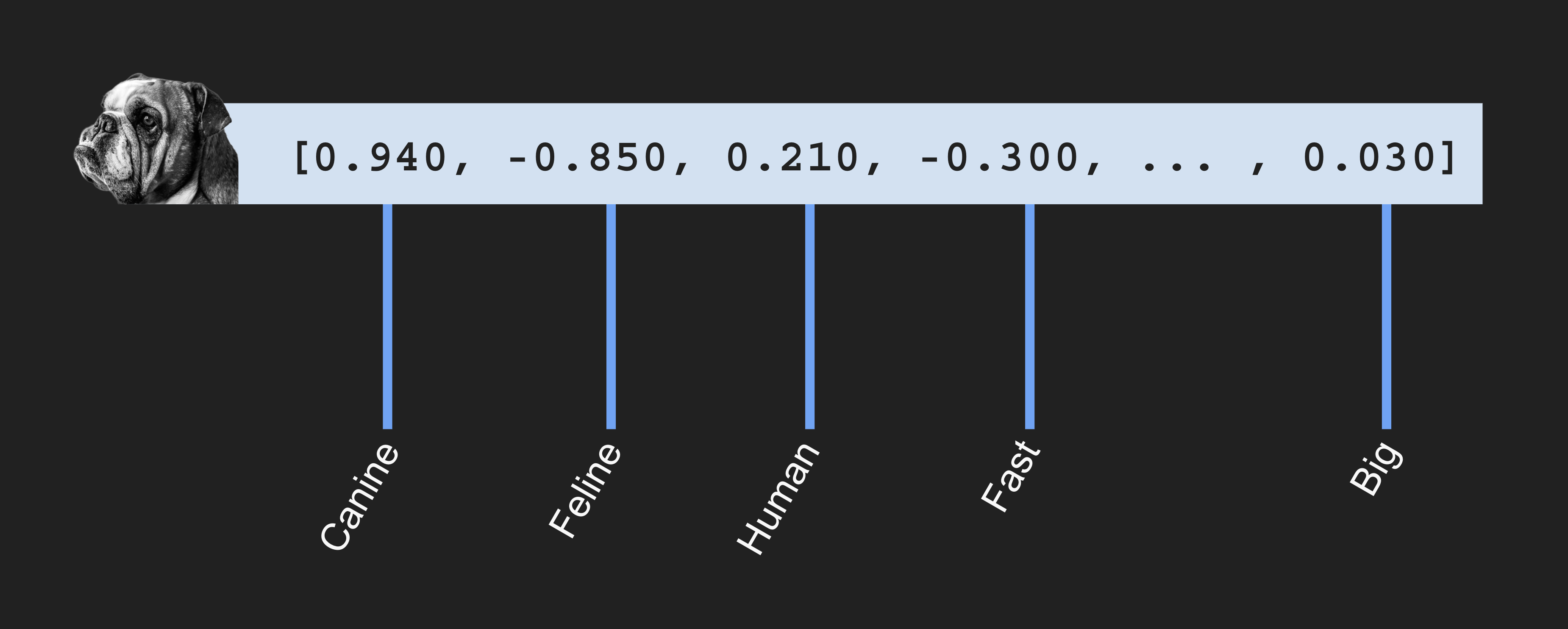
In the previous example, we see the image described in multiple dimensions each representing a distinct feature. We can say the image corresponds to something very canine, not too feline, somewhat human, and so on. We can do the same with a picture of a cat:
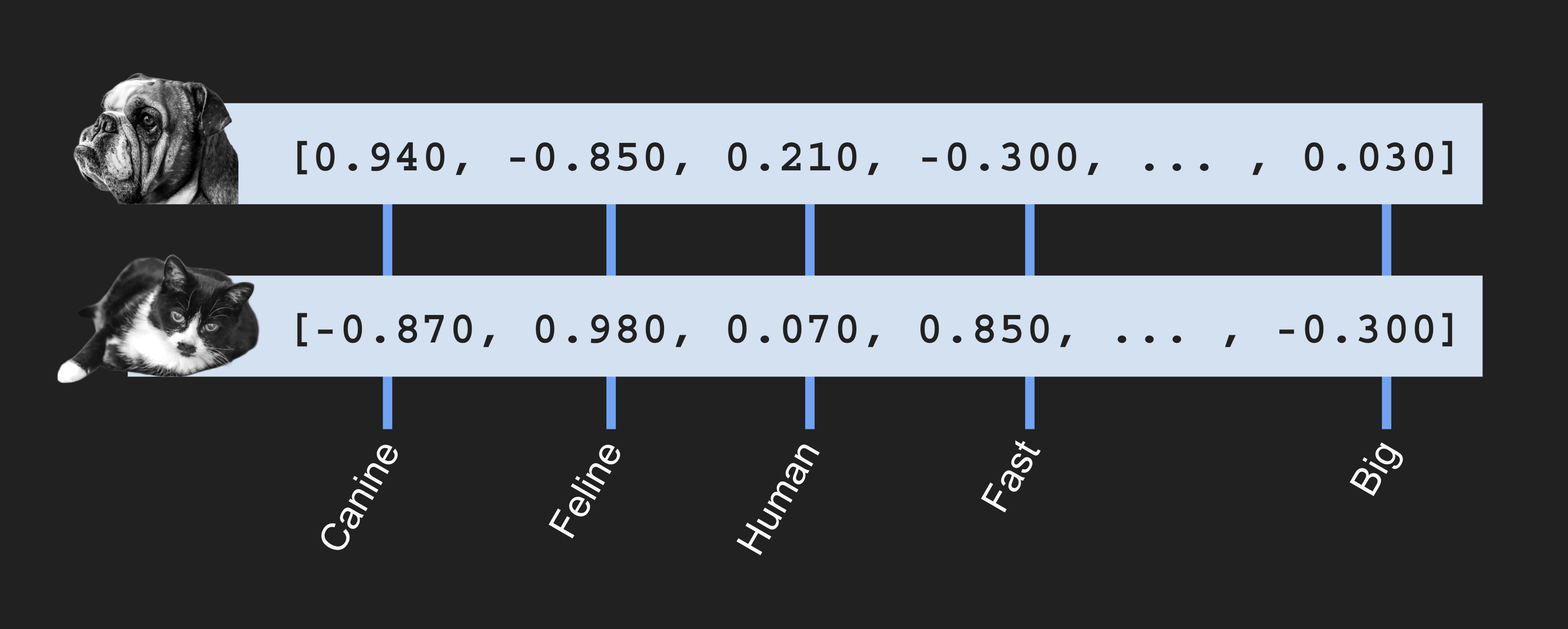
In the context of RAG applications, vectors are created by embedders. An embedder is an AI model that takes text, image, or audio and produces a vector, often with hundreds or thousands of dimensions. When you use an embedder like the ones offered by OpenAI, Gemini, and other, the exact meaning of each dimension is unknown:
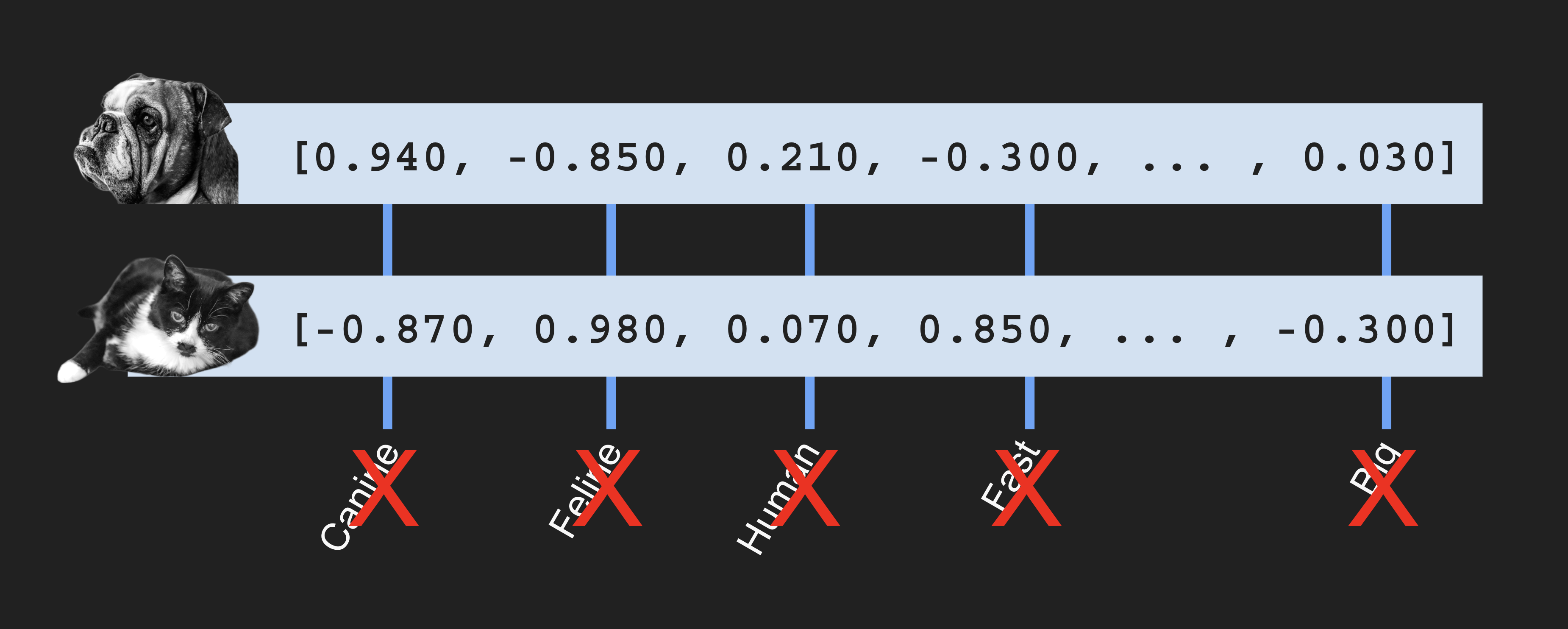
A 2-dimensional example#
To help you grasp the concept better, we are going to use an example with only two dimensions each with a concrete understandable meaning: size and speed. We can place some objects in this space according to their size and speed, and each object can be assigned a vector with concrete numbers on each dimension:
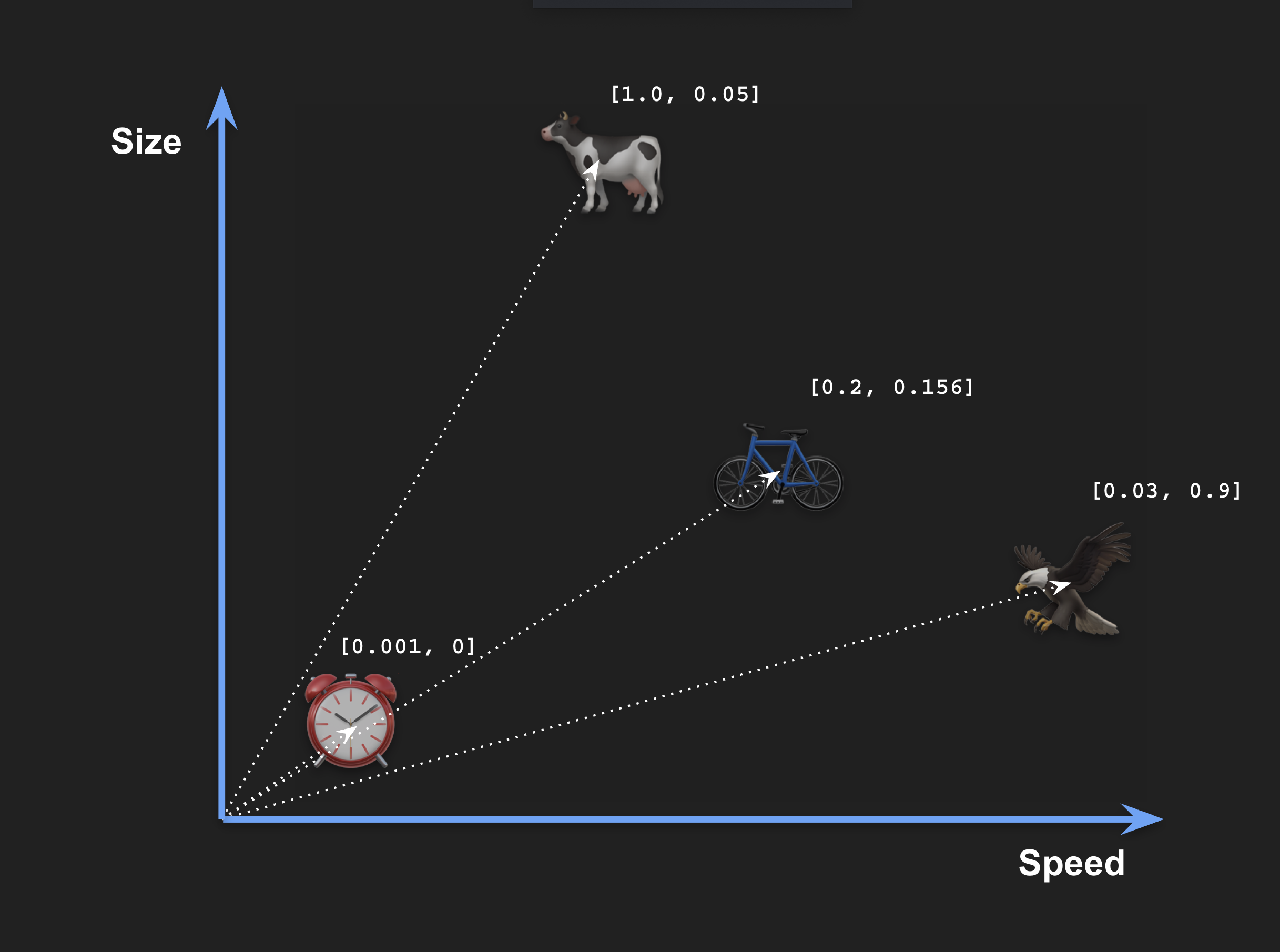
Now we have captured the semantic meaning of these objects using vectors. Again, we assigned concrete features to each dimension, but we don’t truly need to understand the meaning of each dimension when using vector embedders.
Storing vectors in a relational database#
We need to store these vectors somewhere, and a relational database is probably the best option. We’ll use MariaDB which offers reliable storage and performant vector search. It’s also open-source and easy to run on your computer, for example with Docker:
docker run --name mariadb --detach --publish 3306:3306 --env MARIADB_ROOT_PASSWORD='password' --env MARIADB_DATABASE='demo' mariadb:11.7You can connect to this database using a SQL client like DBeaver, or extensions for your IDE. If you like the command line, you can install the MariaDB client. Alternatively you can start a bash session on the container running MariaDB and use the CLI tool from there:
docker exec -it mariadb mariadb -u root -p'password' demoCreate the following table with one column for the object names (name) and another for the two-dimensional vectors (embedding):
USE demo;
CREATE TABLE objects (
name VARCHAR(50),
embedding VECTOR(2)
);Insert the following rows using the coordinates from the diagram above:
INSERT INTO objects (name, embedding)
VALUES
("Alarm clock", VEC_FromText("[0.001, 0]")),
("Cow", VEC_FromText("[1.0, 0.05]")),
("Bicycle", VEC_FromText("[0.2, 0.156]")),
("Eagle", VEC_FromText("[0.03, 0.9]"));The VEC_FromText() function converts a text representation of a vector (in JSON array format) into MariaDB’s VECTOR data type.
Comparing vectors in a relational database (semantic search)#
The point of having vector embeddings is to compare them for similarity search. If we take our two-dimensional example, we can see that big objects tend to appear at the top of the space and small ones at the bottom:
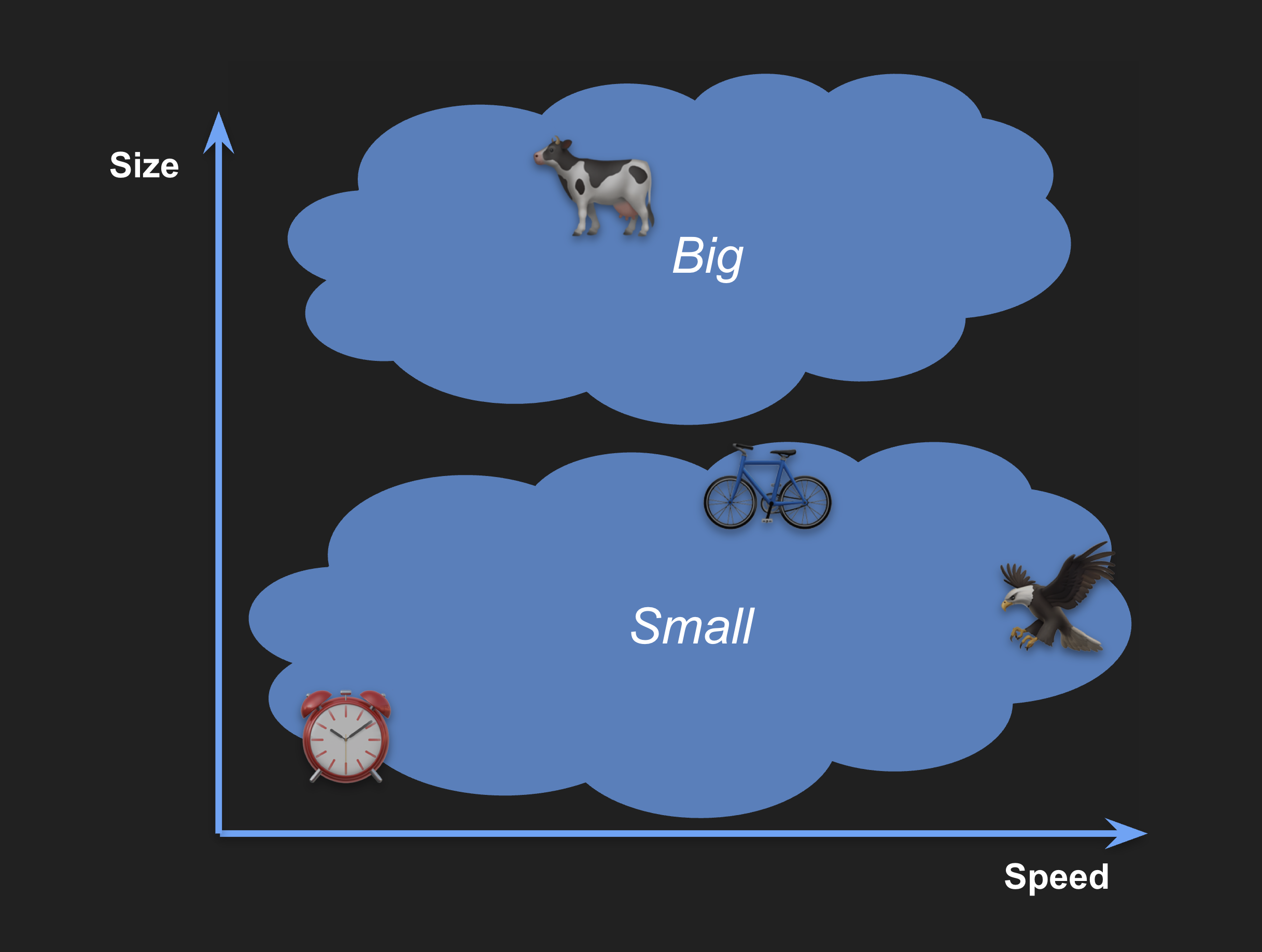
Likewise, objects that are slow will be to the left and objects that are fast to the right:
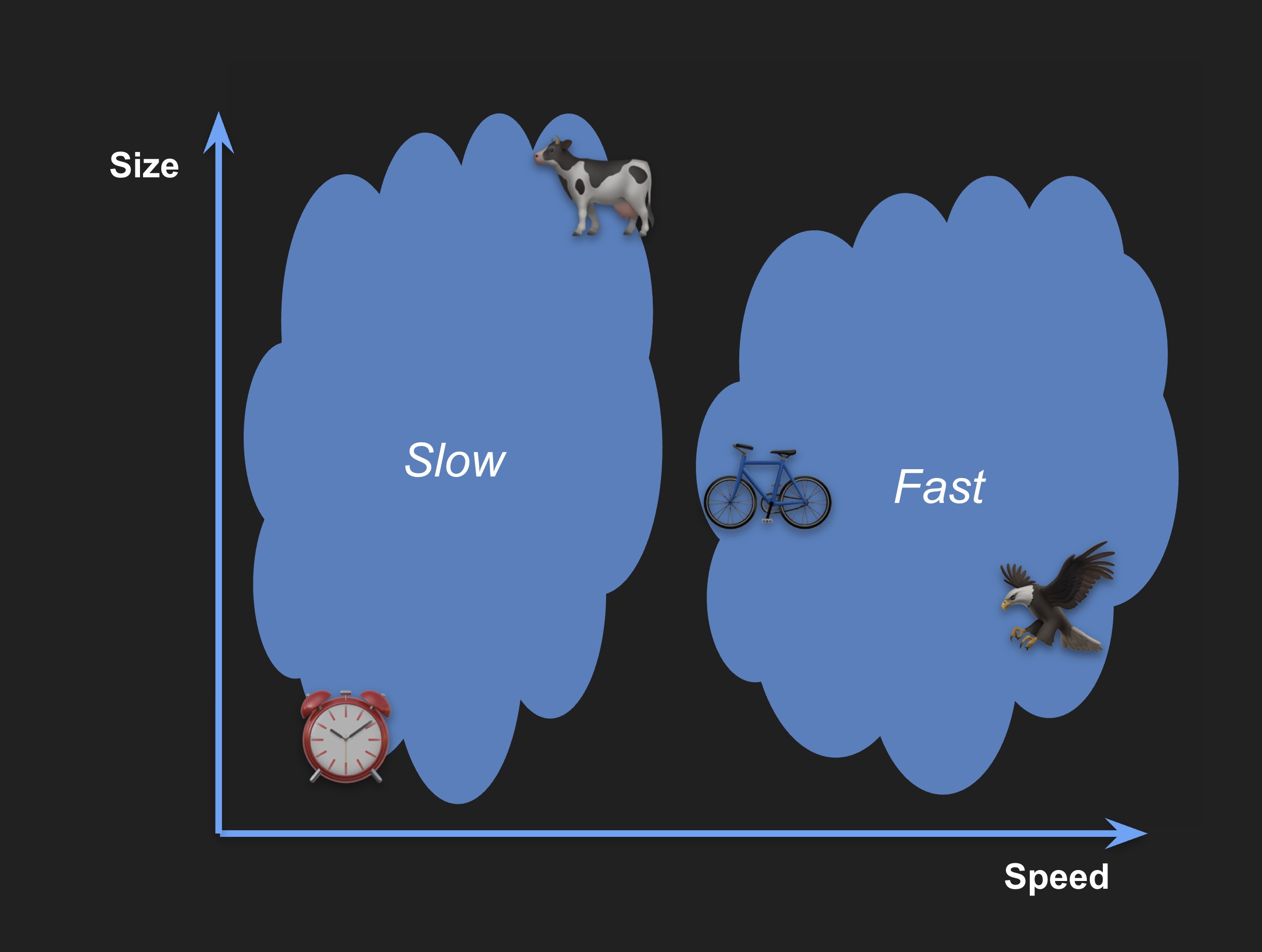
The location of the objects determines how similar they are compared to others:
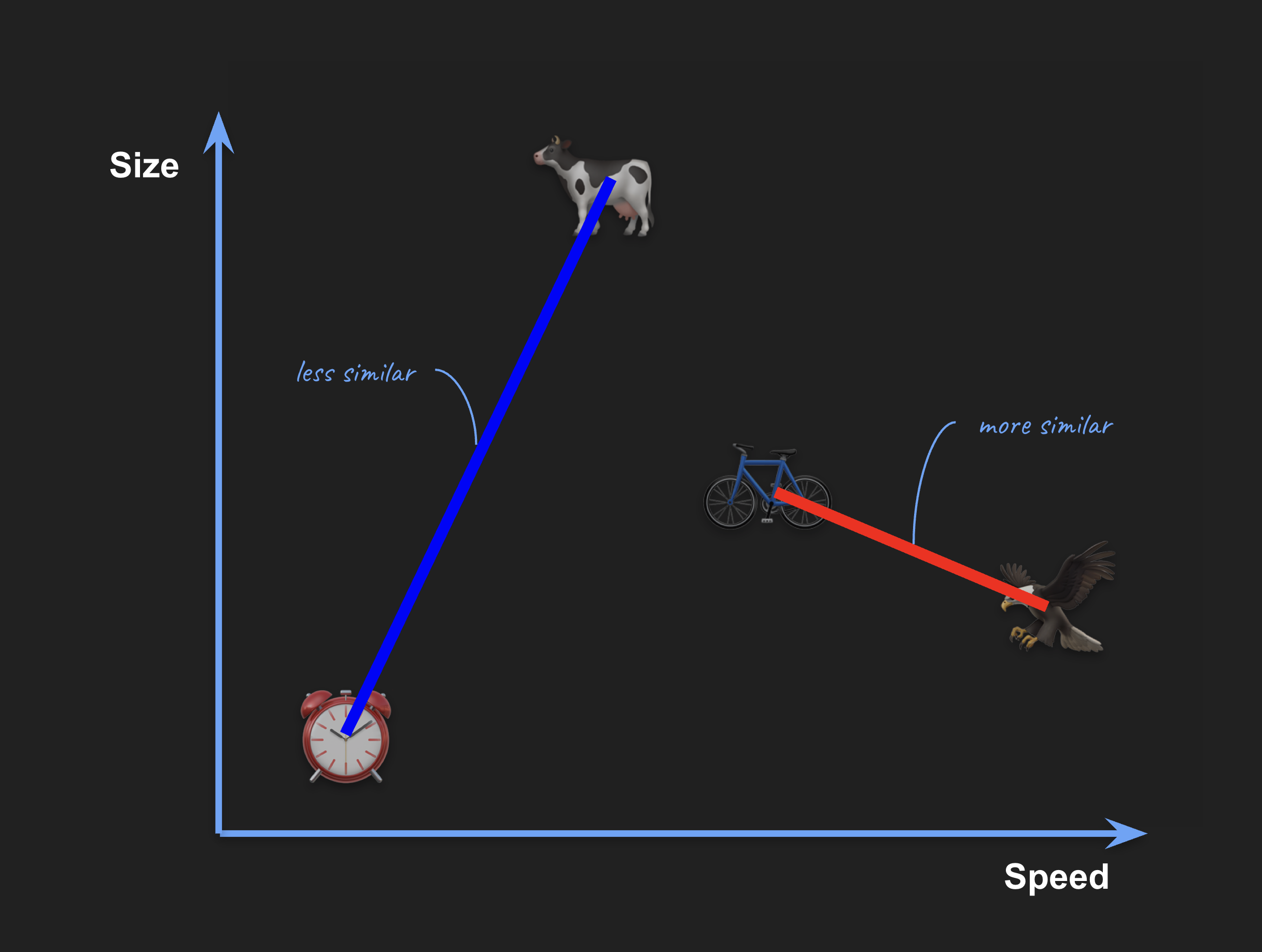
We can use these properties of the space to search for objects that are similar to another. For example, let’s say we want to find the most similar object (in terms of size and speed) to something small and slow. Maybe an ant.
First, we have to calculate the vector for an ant. In practice, we would use an embedder, but this is a theoretical example and we are using our brains and creativity to calculate it. Let’s use the following vector:
[0.01, 0.01]Now we can use this vector in a SQL query:
SELECT name FROM objects
ORDER BY VEC_DISTANCE_EUCLIDEAN(
VEC_FromText("[0.01, 0.01]"),
embedding
)
LIMIT 1;We are ordering the objects in the table by their distance to an ant ([0.01, 0.01]). We limit the results to one row to get the closest one and select only its name. The previous query returns "Alarm Clock".
If you repeat the exercise for an object that is big and not too slow (for example a horse represented as [0.9, 0.5]), the new query would correctly return "Cow":
SELECT name FROM objects
ORDER BY VEC_DISTANCE_EUCLIDEAN(
VEC_FromText("[0.9, 0.5]"),
embedding
)
LIMIT 1; -- "Cow"Use of vectors in RAG#
RAG (Retrieval-Augmented Generation) uses vector embeddings to enhance AI responses with contextually relevant information. Here’s how it works:
Document Processing: Convert your documents, articles, knowledge base, or data into vector embeddings using an embedder model.
Vector Storage: Store these embeddings along with references to the original content in a vector database like MariaDB. Don’t forget to create a vector index to improve performance.
Query Processing: When a user asks a question, convert their query into a vector embedding using the same embedder.
Similarity Search: Perform a vector similarity search (like we did with our 2D example) to find the most relevant pieces of data:
SELECT document_id, content
FROM documents
ORDER BY VEC_DISTANCE_COSINE(
VEC_FromText("[0.1, 0.2, ..., 0.9]"), -- Query vector from embedder
embedding
)
LIMIT 5;- Augmented Generation: Feed the retrieved content along with the user’s question to an LLM (like GPT-4 or Llama 3), which generates a response based on both the query and the retrieved information.
The advantage of RAG is that it doesn’t require you to train or fine-tune an LLM to learn your data. Instead, it retrieves relevant information on demand and feeds it to the AI model at inference time.
For a brush-up on AI concepts for building GenAI applications, watch my webinar on the topic.
Enjoyed this post? I can help your team implement similar solutions—contact me to learn more.

