
En el contexto de aplicaciones de GenAI, una incrustación vectorial (vector embedding o simplemente vector) es una secuencia de números asociada a ciertos datos. Esta secuencia de números captura el significado semántico de los datos asociados, y cada número representa una característica. Por ejemplo, el siguiente es un vector que representa una imagen de un perro:
En el ejemplo anterior, vemos la imagen descrita en múltiples dimensiones, cada una representando una característica distinta. Podemos decir que la imagen corresponde a algo muy canino, no muy felino, algo humano, y así sucesivamente. Podemos hacer lo mismo con una imagen de un gato:
En el contexto de aplicaciones RAG, los vectores son creados por embedders. Un embedder es un modelo de IA que toma texto, imagen o audio y produce un vector, usualmente con cientos o miles de dimensiones. Cuando usas un embedder como los que ofrecen OpenAI, Gemini y otros, el significado exacto de cada dimensión es desconocido:
Un ejemplo bidimensional#
Para ayudarte a comprender mejor el concepto, vamos a usar un ejemplo con solo dos dimensiones, cada una con un significado concreto y comprensible: Tamaño y velocidad. Podemos ubicar algunos objetos en este espacio según su tamaño y velocidad. A cada objeto se le puede asignar un vector con números concretos en cada dimensión:
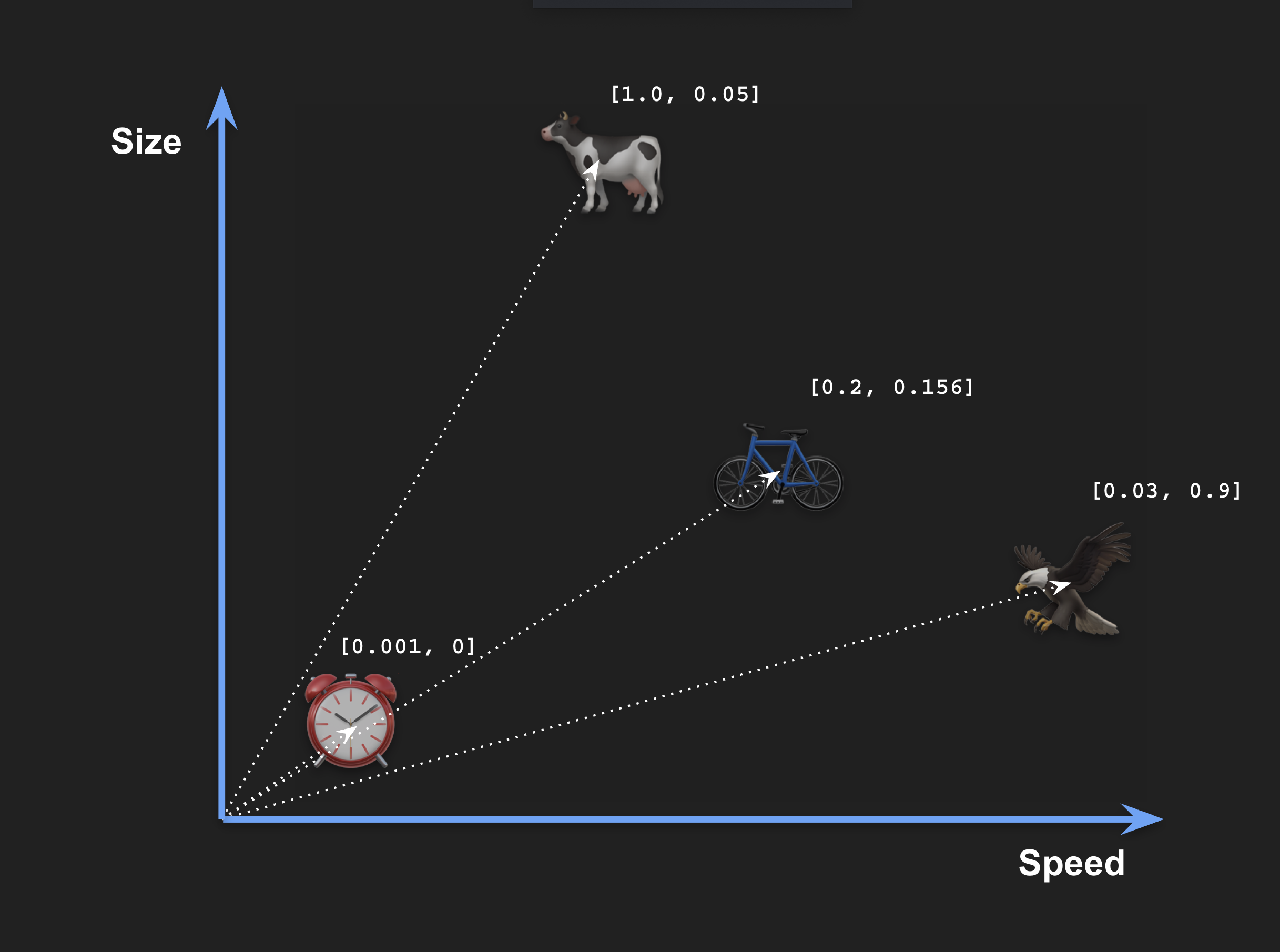
Ahora hemos capturado el significado semántico de estos objetos usando vectores. Nuevamente, asignamos características concretas a cada dimensión, pero no es necesario comprender el significado de cada una al usar embedders vectoriales.
Almacenando vectores en una base de datos relacional#
Necesitamos almacenar estos vectores en algún lugar, y una base de datos relacional es probablemente la mejor opción. Usaremos MariaDB, que ofrece almacenamiento confiable y búsqueda vectorial de alto rendimiento. También es de código abierto y fácil de ejecutar en tu computadora, por ejemplo con Docker:
docker run --name mariadb --detach --publish 3306:3306 --env MARIADB_ROOT_PASSWORD='password' --env MARIADB_DATABASE='demo' mariadb:11.7Puedes conectarte a esta base de datos usando un cliente SQL como DBeaver o extensiones para tu IDE. Si prefieres la línea de comandos, puedes instalar el cliente de MariaDB. Alternativamente, puedes iniciar una sesión bash en el contenedor que ejecuta MariaDB y usar allí la herramienta de CLI:
docker exec -it mariadb mariadb -u root -p'password' demoCrea la siguiente tabla con una columna para los nombres de los objetos (name) y otra para los vectores bidimensionales (embedding):
USE demo;
CREATE TABLE objects (
name VARCHAR(50),
embedding VECTOR(2)
);Inserta las siguientes filas usando las coordenadas del diagrama anterior:
INSERT INTO objects (name, embedding)
VALUES
("Alarm clock", VEC_FromText("[0.001, 0]")),
("Cow", VEC_FromText("[1.0, 0.05]")),
("Bicycle", VEC_FromText("[0.2, 0.156]")),
("Eagle", VEC_FromText("[0.03, 0.9]"));La función VEC_FromText() convierte una representación textual de un vector (en formato de arreglo JSON) al tipo de dato VECTOR de MariaDB.
Comparación de vectores en una base de datos relacional (búsqueda semántica)#
El propósito de tener vectores es compararlos para hacer búsquedas de similitud. Si tomamos nuestro ejemplo bidimensional, podemos ver que los objetos grandes tienden a aparecer en la parte superior del espacio y los pequeños en la parte inferior:
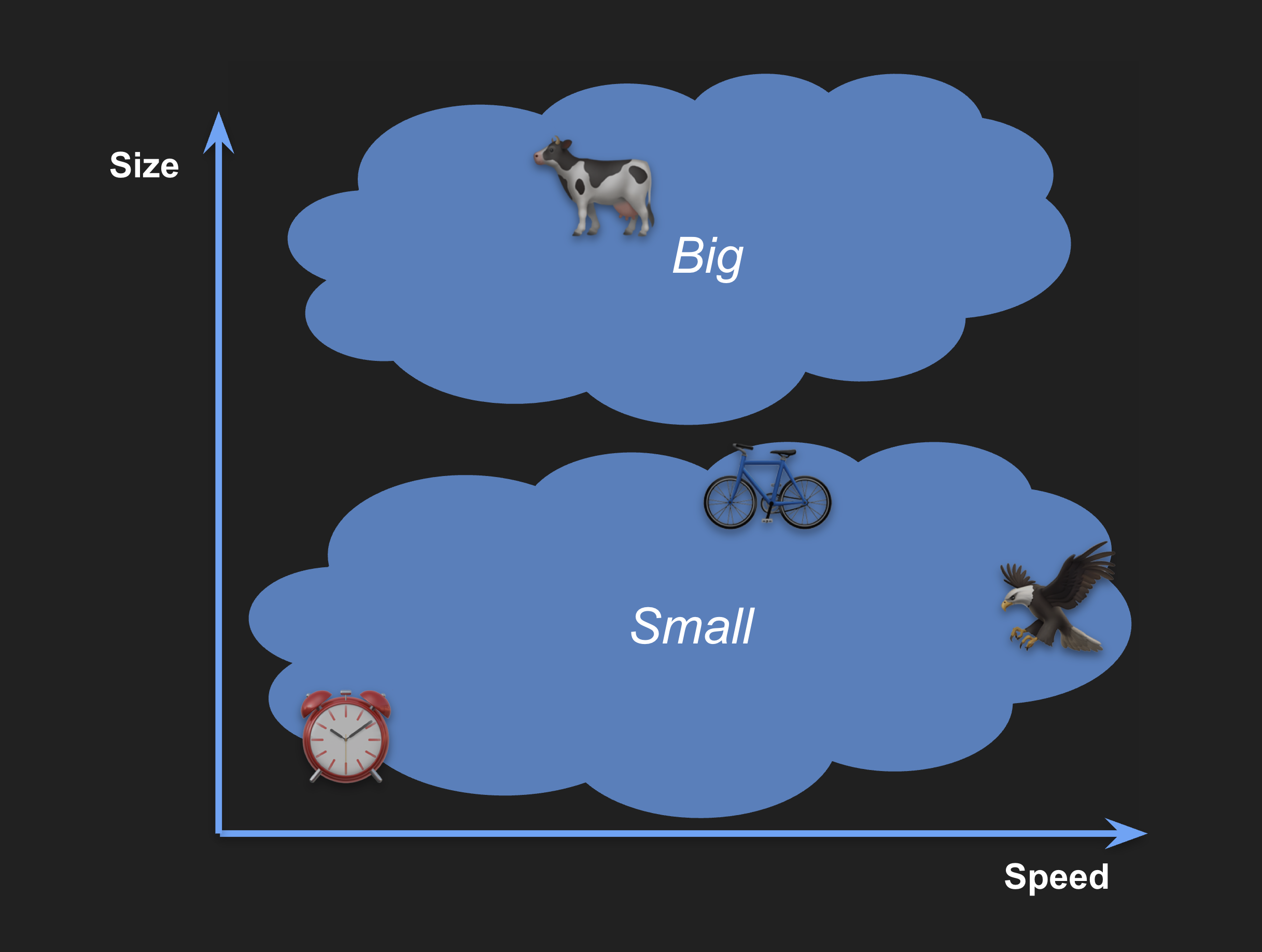
Asimismo, los objetos lentos estarán a la izquierda y los rápidos a la derecha:
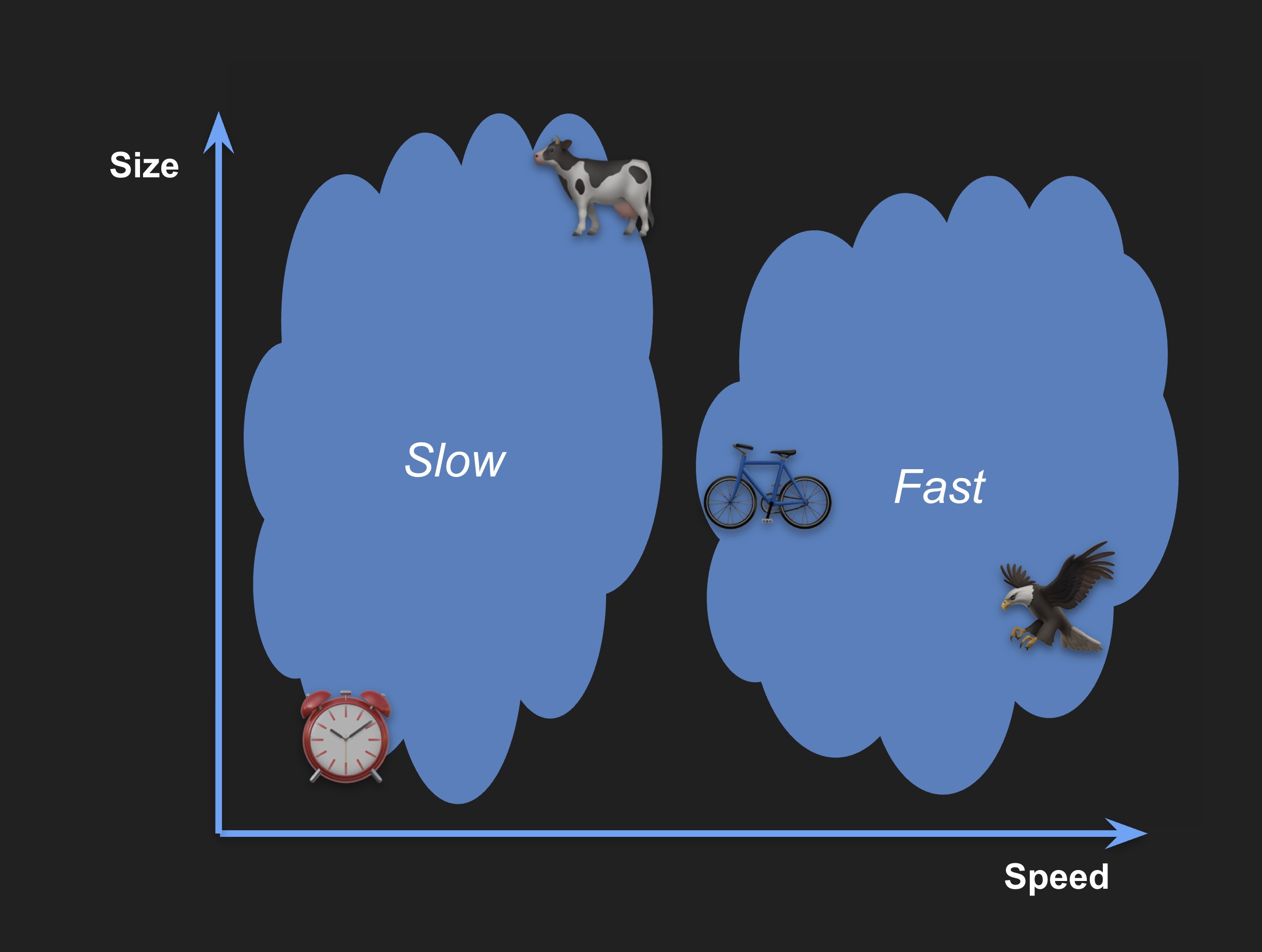
La ubicación de los objetos determina cuán similares son entre sí:
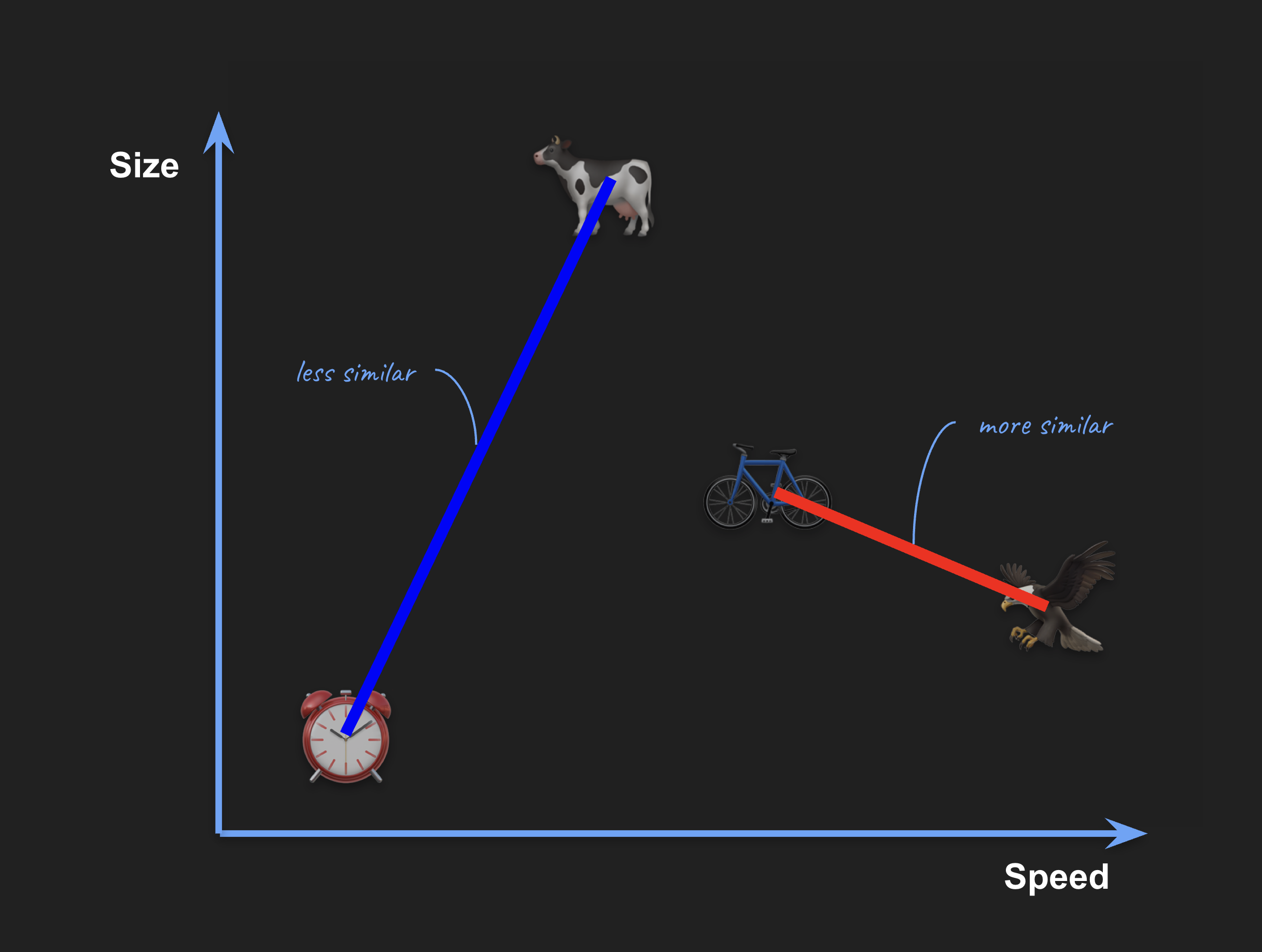
Podemos usar estas propiedades del espacio para buscar objetos similares a otro. Por ejemplo, supongamos que queremos encontrar el objeto más similar (en términos de tamaño y velocidad) a algo pequeño y lento. Tal vez una hormiga.
Primero, tenemos que calcular el vector para una hormiga. En la práctica, usaríamos un embedder, pero este es un ejemplo teórico y estamos usando nuestro cerebro y creatividad para calcularlo. Usemos el siguiente vector:
[0.01, 0.01]Ahora podemos usar este vector en una consulta SQL:
SELECT name FROM objects
ORDER BY VEC_DISTANCE_EUCLIDEAN(
VEC_FromText("[0.01, 0.01]"),
embedding
)
LIMIT 1;Estamos ordenando los objetos de table por su distancia a una hormiga ([0.01, 0.01]). Limitamos los resultados a una fila para obtener el más cercano y seleccionamos sólo su nombre. La consulta anterior retorna "Alarm Clock".
Si repites el ejercicio para un objeto que es grande y no muy lento (por ejemplo, un caballo representado como [0.9, 0.5]), la nueva consulta retornará correctamente "Cow":
SELECT name FROM objects
ORDER BY VEC_DISTANCE_EUCLIDEAN(
VEC_FromText("[0.9, 0.5]"),
embedding
)
LIMIT 1; -- "Cow"Uso de vectores en RAG#
RAG (Generación Aumentada por Recuperación) usa vectores para mejorar las respuestas de un modelo IA con información contextual relevante. Así es como funciona:
Procesamiento de documentos: Convierte tus documentos, artículos o datos en vectores usando un modelo embedder.
Almacenamiento de vectores: Almacena estos vectores junto con referencias al contenido original en una base de datos vectorial como MariaDB. No olvides crear un índice vectorial para mejorar el rendimiento.
Procesamiento de consultas: Cuando un usuario hace una pregunta, convierte su consulta en un vector usando el mismo embedder.
Búsqueda por similitud: Realiza una búsqueda por similitud vectorial (como hicimos en el ejemplo 2D) para encontrar los datos más relevantes:
SELECT document_id, content
FROM documents
ORDER BY VEC_DISTANCE_COSINE(
VEC_FromText("[0.1, 0.2, ..., 0.9]"), -- Vector de la consulta generado por el embedder
embedding
)
LIMIT 5;- Generación aumentada: Envía el contenido recuperado junto con la pregunta del usuario a un LLM (como GPT-4 o Llama 3), que generará una respuesta basada en ambos.
La ventaja de RAG es que no necesitas entrenar ni ajustar un LLM para que conozca tus datos. En su lugar, RAG recupera la información relevante bajo demanda y la entrega al modelo de IA en tiempo de inferencia.
Para repasar conceptos clave de IA para construir aplicaciones GenIA, mira mi webinar sobre el tema.
¿Te gustó este artículo? Puedo ayudar a tu equipo a implementar soluciones similares. Contáctame para saber más.