
Nota: Traducido de la versión original en Inglés.
Las aplicaciones críticas de negocio requieren alta disponibilidad. El objetivo de la alta disponibilidad es proporcionar a los usuarios acceso constante a servicios o recursos, minimizando las posibilidades de interrupción. La conmutación por error automática es un mecanismo específico utilizado para lograr alta disponibilidad. Esto implica detectar automáticamente el fallo de un componente del sistema (como un servidor, red o base de datos) e inmediatamente cambiar las operaciones, sin que halla intervención humana, a un componente de respaldo. Esto aumenta la resiliencia.
MariaDB MaxScale es un proxy de base de datos que incluye características para alta disponibilidad. En este artículo, mostraré cómo puedes probarlo con una aplicación que simula una tienda en línea implementada en Java y Svelte.
Arquitectura#
El siguiente diagrama muestra la arquitectura de la aplicación de demostración:

Una aplicación web desarrollada con JavaScript y el framework Svelte realiza solicitudes HTTP a un backend en Java. El backend responde con eventos enviados por el servidor que el frontend utiliza para actualizar la interfaz de usuario en el navegador.
El backend está implementado con Spring Boot y se conecta a un clúster de bases de datos MariaDB usando R2DBC (reactivo). La lógica del backend es, en resumen, una simulación de lecturas y escrituras esobre una base de datos de una tienda en línea. La simulación está parametrizada, y el usuario puede ajustar:
- Visitas de productos por minuto: Cuántas lecturas a la base de datos por minuto.
- Pedidos por minuto: Cuántas escrituras a la base de datos por minuto.
- Productos por pedido: Amplificación de escritura.
- Tiempo de espera en milisegundos: Cuántos segundos hasta que una solicitud a la base de datos se considere fallida.
El clúster de bases de datos está precedido por un proxy de base de datos llamado MaxScale. Este proxy hace que el clúster parezca una única base de datos lógica para el backend de Java. MaxScale también realiza división de lectura/escritura (enviando escrituras al servidor primario de MariaDB y lecturas a las réplicas), así como equilibrio de carga de lecturas entre servidores réplicas usando un algoritmo configurable. Los datos se replican automáticamente desde el servidor primario a los servidores de base de datos réplica.
Construyendo las imágenes Docker desde el código fuente#
Preparé algunas imágenes Docker para cada componente en el simulador. Puedes construir las imágenes desde el código fuente (opcional) o usar las imágenes ya construidas y publicadas en Docker Hub. Si decides construir las imágenes tú mismo, puedes encontrar el código fuente en GitHub:
Despliegues de MariaDB: Imágenes personalizadas para el despliegue fácil de topologías replicadas de MariaDB con MaxScale. ¡NO LAS USES EN PRODUCCIÓN!. Estas imágenes son adecuadas solo para aplicaciones de demostración. Usa las imágenes Docker oficiales de MariaDB para despliegues en producción.
Aplicación backend: La aplicación backend que se connecta al cluster de bases de datos.
Aplicación frontend: La aplicación frontend que hace requests de configuración de la simulación al backend y que recibe eventos para mostrar el resultado de la simulación.
Cada repositorio tiene Dockerfiles que puedes usar para construir tus propias imágenes Docker. Por ejemplo, para construir la imagen de la aplicación backend, ejecuta:
docker build --tag alejandrodu/online-store-simulator-java-backend .Ejecutando la simulación#
Todos los servicios pueden iniciarse utilizando el siguiente archivo Docker Compose (docker-compose.yml):
version: "3.9"
services:
server-1:
container_name: server-1
image: alejandrodu/mariadb
ports:
- "3306:3306"
environment:
- MARIADB_CREATE_DATABASE=demo
- MARIADB_CREATE_USER=user:Password123!
- MARIADB_CREATE_REPLICATION_USER=replication_user:ReplicationPassword123!
- MARIADB_CREATE_MAXSCALE_USER=maxscale_user:MaxScalePassword123!
server-2:
container_name: server-2
image: alejandrodu/mariadb
ports:
- "3307:3306"
environment:
- MARIADB_REPLICATE_FROM=replication_user:ReplicationPassword123!@server-1:3306
server-3:
container_name: server-3
image: alejandrodu/mariadb
ports:
- "3308:3306"
environment:
- MARIADB_REPLICATE_FROM=replication_user:ReplicationPassword123!@server-1:3306
maxscale:
container_name: maxscale
image: alejandrodu/mariadb-maxscale
command: --admin_host 0.0.0.0 --admin_secure_gui false
ports:
- "4000:4000"
- "8989:8989"
- "27017:27017"
environment:
- MAXSCALE_USER=maxscale_user:MaxScalePassword123!
- MARIADB_HOST_1=server-1 3306
- MARIADB_HOST_2=server-2 3306
- MARIADB_HOST_3=server-3 3306
healthcheck:
test: ["CMD", "maxctrl", "list", "servers"]
interval: 5s
timeout: 10s
retries: 5
java-backend:
container_name: java-backend
image: alejandrodu/online-store-simulator-java-backend
ports:
- "8080:8080"
environment:
- spring.r2dbc.url=r2dbc:mariadb://maxscale:4000/demo
- spring.r2dbc.username=user
- spring.r2dbc.password=Password123!
- spring.liquibase.url=jdbc:mariadb://maxscale:4000/demo
- spring.liquibase.user=user
- spring.liquibase.password=Password123!
depends_on:
maxscale:
condition: service_healthy
svelte-frontend:
container_name: svelte-fronted
image: alejandrodu/online-store-simulator-svelte-frontend
ports:
- "5173:80"
environment:
- BACKEND_URL=http://java-backend:8080Cambia al directorio en el que se encuentra el archivo Docker Compose y inicia los servicios en modo “detached” de la siguiente manera:
docker compose up -dConfigurando MaxScale#
Antes de comenzar la simulación, configura MaxScale para la repetición de transacciones. Ajusta también los tiempos de espera para hacer la simulación más interesante.
Navega a http://localhost:8989/ e inicia sesión en la UI usando:
- Usuario:
admin - Contraseña:
mariadb
Verás un panel de control con el estado del clúster de MariaDB.
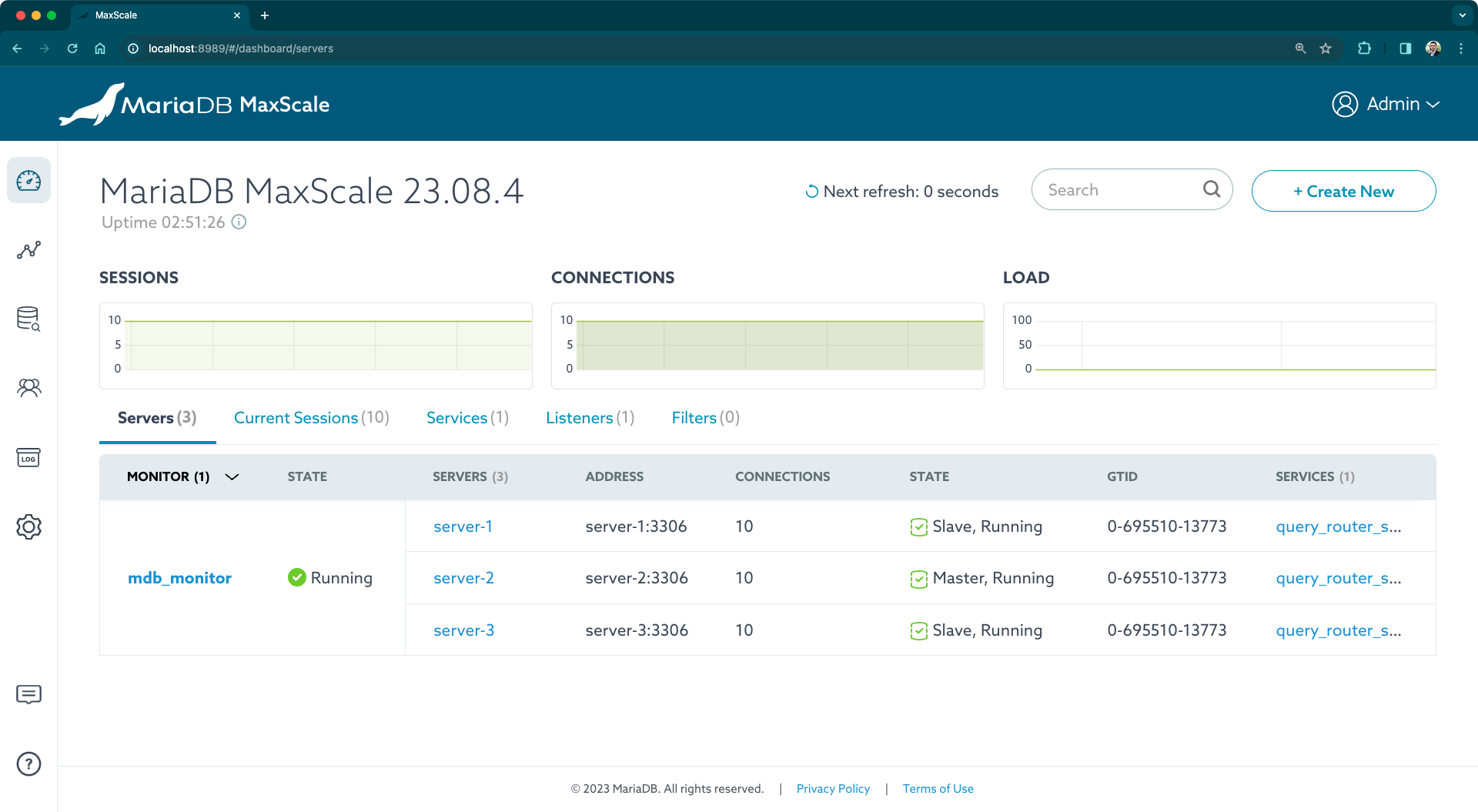
Hay un servidor primario (server-1), y dos réplicas (server-2 y server-3). La replicación ya está configurada desde server-1 (primario) a server-2 y server-3 (réplicas). Todos los servidores deberían estar funcionando.
Haz clic en mdb_monitor y luego en el icono de lápiz para habilitar la edición de parámetros. Configura los siguientes parámetros:
auto_failover(true): Esto habilita la conmutación por fallo automática. Cuando un servidor MariaDB está caído, MaxScale selecciona un servidor réplica y lo reconfigura como el nuevo primario para que las escrituras puedan continuar ocurriendo.auto_rejoin(true): Esto habilita la reincorporación automática de servidores recuperados. Cuando un servidor fallido vuelve a estar en línea, MaxScale lo detecta y lo configura como un servidor réplica disponible.failcount(1): Establece el número de iteraciones del monitor (un componente en MaxScale que verifica el estado de los servidores) requeridas para que un servidor sea considerado caído y activar el proceso de fallo automático. Establecemos un valor de1para asegurar que el fallo automático comience inmediatamente después del fallo.backend_connect_timeout(1000): Tiempo de espera para conexiones del monitor. Establecemos un valor bajo (un segundo) para activar rápidamente el fallo automático en esta demo.backend_read_timeout(1000): Tiempo de espera para lecturas del monitor.backend_write_timeout(1000): Tiempo de espera para escrituras del monitor.master_failure_timeout(1000): Tiempo de espera para fallo del primario.monitor_interval(1000): Frecuencia con la que se monitorean los servidores.
⚠️ ADVERTENCIA: ¡Estos valores son apropiados para esta demostración pero muy probablemente no sean los mejores para entornos de producción!
Una vez establecidos los parámetros, haz clic en Done Editing y Confirm.
También necesitas habilitar la repetición de transacciones, que re-ejecuta automáticamente transacciones en vuelo en servidores que se cayeron justo después de que se encaminara una sentencia SQL. Esta es una característica útil para desarrolladores de software ya que previene la necesidad de codificar casos de fallo y reintentar transacciones.
En el menú principal, haz clic en Dashboard y luego en cualquiera de los enlaces query_router_service en la lista de servidores. Edita los parámetros de la siguiente manera:
transaction_replay(true): Activa el reintento automático de transacciones fallidas.transaction_replay_retry_on_deadlock(true): Lo mismo que el anterior cuando ocurre un bloqueo.transaction_replay_retry_on_mismatch(true): Lo mismo que el anterior cuando ocurre una discrepancia de suma de comprobación (checksum).
Una vez establecidos los parámetros, haz clic en Done Editing y Confirm.
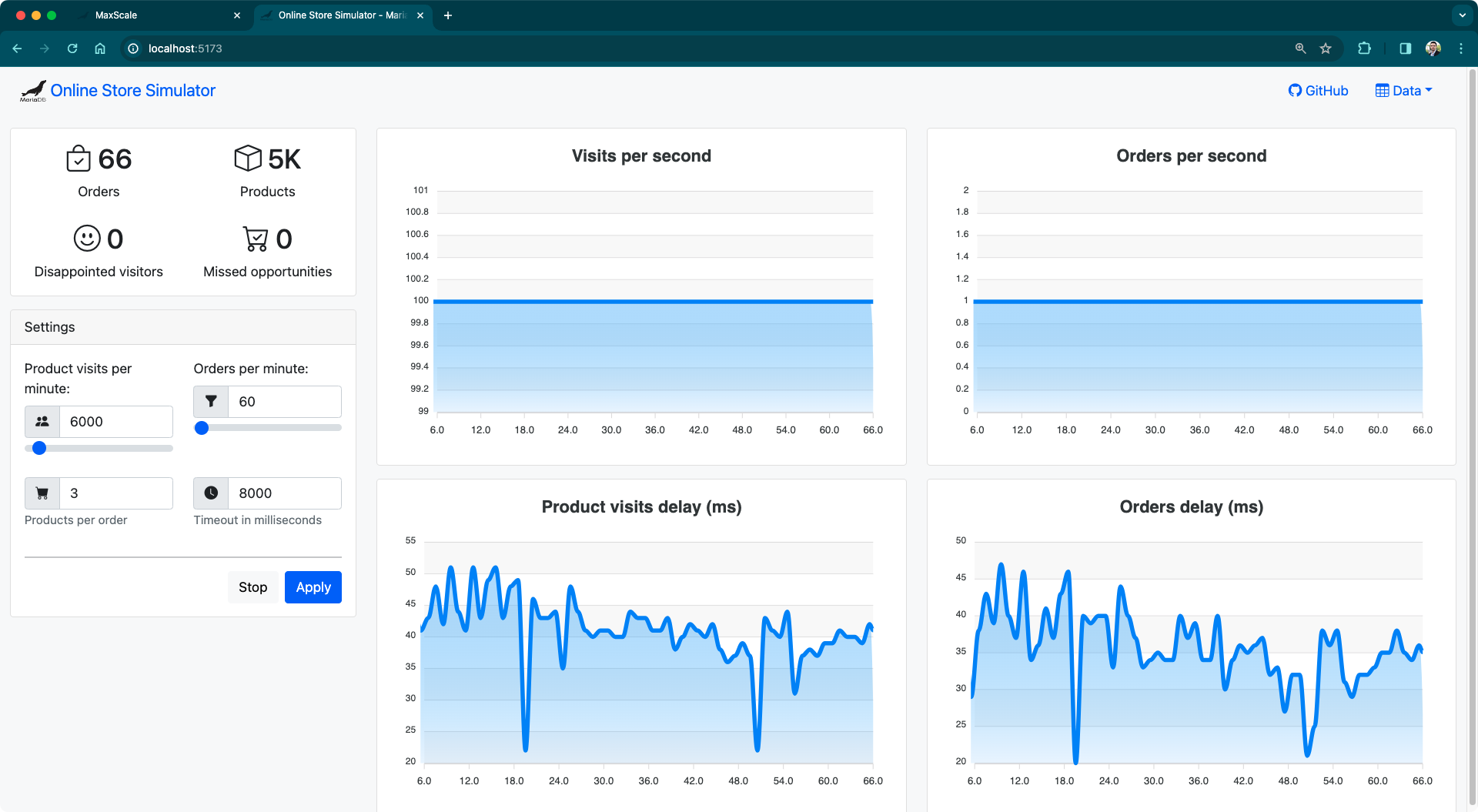
Con todo configurado, ya puedes iniciar la simulación. Navega a http://localhost:5173/ y configura los siguientes parámetros (los nombres son, espero, autoexplicativos):
- Visitas de productos por minuto (Product visits per minute):
6000 - Pedidos por minuto (Orders per minute):
60 - Tiempo de espera en milisegundos (Timeout in milliseconds):
8000
Pero antes de iniciar la simulación, necesitas crear los productos para la tienda en línea. Haz clic en Data | Create products…. Deja los valores predeterminados y haz clic en Create. Deberías ver la interfaz de usuario actualizándose a medida que los productos son creados en la base de datos.
Ahora finalmente puedes hacer clic en Start y ver la simulación en acción.
Simulando una falla de servidor#
En este punto, el servidor primario está manejando las escrituras (pedidos). ¿Qué sucede si detienes ese servidor? En la línea de comandos ejecuta:
docker stop server-1Dependiendo de múltiples factores, podrías obtener tan solo algunos “visitantes decepcionados” o incluso algunas “oportunidades perdidas” en el simulador. ¡O tal vez no obtengas ninguno en absoluto! Las visitas a productos (lecturas) y los pedidos (escrituras) continúan sucediendo gracias a MaxScale. Sin conmutación por fallo automática, tendrías que reconfigurar todo manualmente, lo cual resulta en más tiempo de inactividad y en muchos visitantes decepcionados y oportunidades perdidas.
Inicia el servidor fallido:
docker start server-1Ve al Dashboard de MaxScale (http://localhost:8989/) y verifica que server-1 ahora es una réplica funcional.
Puedes realizar un cambio manual para hacer que server-1 sea nuevamente el servidor primario. Haz clic en mdb_monitor y luego pasa el cursor sobre la sección MASTER. Haz clic en el icono de lápiz y selecciona server-1. Haz clic en Swap y verifica nuevamente en el Dashboard que el nuevo servidor primario es server-1.
Conclusión#
La conmutación por fallo automática es solo uno de los componentes en sistemas de alta disponibilidad. Puedes usar un proxy de base de datos como MaxScale para configurar el fallo automático, pero también otros componentes como el equilibrio de carga, enrutamiento de consultas, reintento de transacciones, aislamiento de topología y más. Consulta la documentación en https://mariadb.com/kb/en/maxscale/.
¿Te gustó este artículo? Puedo ayudar a tu equipo a implementar soluciones similares. Contáctame para saber más.

